
When 10 Quadrillion Is Not Enough: The Napkin Analytics Behind AI's "Data Crisis"


The post+chart below showed up a few days ago, saying that LLMs were running out of tokens — words — to learn from.
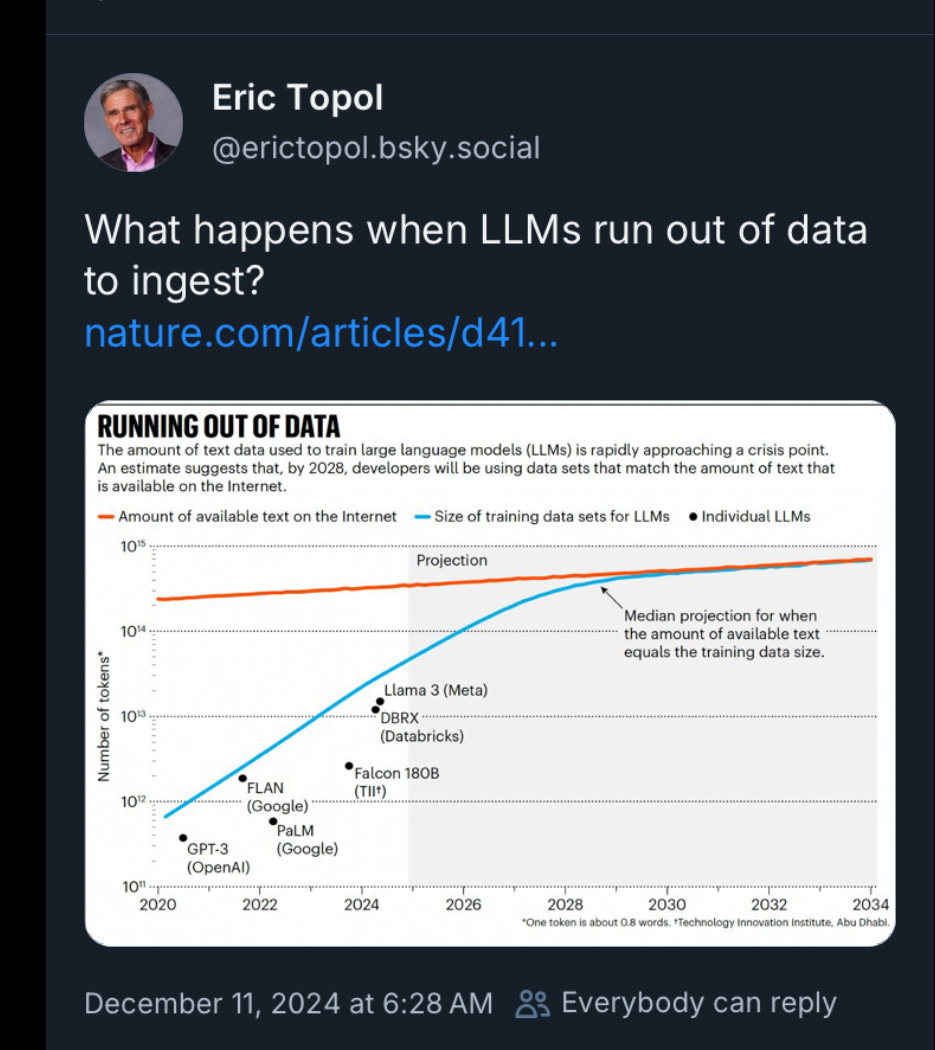
The chart’s text claims we are approaching a crisis.
What does a crisis look like?
LLMs are, at their heart, next-word predictors: “The quick brown fox jumps over the lazy … “
They rely on text data—ordinary web pages, PDFs, newspaper articles—as input into their training models. The algorithms reference this unimaginably large text volume to create the output, in this case, “dog.”
In general, more text improves models in two ways:
They get more accurate at what they do - fewer hallucinations and errors. I wrote about this a few months ago in my Strawberry essay. [Link]
They will be able to address new subject areas. For example, if a model could be trained on the entirety of the DSM-5 manuals, it could offer diagnoses to collections of symptoms. This is less fanciful than you might imagine. Already people are trialing solutions that perform full body scans of a person and identify and categorize every mole on that body for its skin cancer risk. In less than a second. [Related]
Do we have a path forward?
For sure, the models themselves - the algorithms - have been making great strides, as this synopsis explains. [Link]
However, what about net new sources of input material? Could we heal this purported “lack of words” issue by digitizing books and making their content available online? And, what if we can’t?
Examining the recent Google/Harvard announcement
This recent announcement in TechCrunch suggests the beginning of something significant - digitizing all the world’s printed material.
Will that solve our “text input crisis”? Time for Napkin Analytics!
When is 10 quadrillion too small?
How much-printed material is there?
Back in 2023, ISBNdb riffed on Google’s 2010 estimate to come up with a count of 150MM titles, plus or minus. [Link]
Estimates for the # of words in a book vary, by genre and source. Let’s go with an average of 75,000. [Link]
Napkin Math time:
\(150 * 10^6 * 75 * 10^3 = (150 * 75) * 10^(6+3) = 11,250 * 10^9 \)\(11,250 * 10^9 \sim 10 \ quadrillion\ words\)
That’s a lot of words, assuming they could all be digitized and made available.
Let’s put it in context. How many words are on the web?
Back in 2016, Google cited a figure of 130 trillion pages known, if not indexed. [Link]
Let’s assume each page has about 500 words.
That’s 65 quadrillion words
How does this compare?
We have 10 quadrillion words in books and 65 quadrillion words estimated to be known on the web.
So, “words in books” adds (10/65* 100). That’s about +15%.
There’s a lot of hair on these numbers:
The number of books & duplicates of them - different imprints, versions, or bindings.
Printed content that is also available online.
The number of words in a book.
Number of unique web pages available for indexing & scraping.
The passage of time. These figures are based on estimates that date back most of a decade.
But the point is that digitizing the world’s printed media will not produce many new words/concepts/tokens.
Caveat: there may be niche technical areas where significant new digitized content will become available as input into these models.
TL;DR: digitizing the entire known world of books and adding it to the internet probably will not meaningfully change the shape and performance of these models.
Why is the recent Google announcement important?
Key in that announcement is the phrase “public domain.” There is mounting concern about how GenAI companies have inappropriately used digital content. Here’s a useful synopsis sourced, ironically enough, from ChatGPT.
Progressive CDOs and CTOs are mindful of this. This public-domain initiative ensures that companies can create their private models without the risk of taint from the inclusion of copyrighted materials.
Side note: this issue is congruent with how we learned to protect and share intellectual property with open-source licensing models.
Prudent CDOs will plan for GenAI-based applications that are not dependent on training material to which those applications may not have access in the future.
Where do we go from here?
Given that there is no appreciable new text available from printed matter, where will improved performance need to come from?
Improvements to existing algorithms.
New classes of algorithms.
One of my favorite authors on this topic is Gary Marcus. As far back as 2022, he wrote about scaling limitations with LLMs. Fortunately, he also proposes a path forward, using classes of algorithms different from the industry’s current “state of the art.”
That’s not to say that the current class of algorithms and the tools built on top of them aren’t useful - they are. Just as with every tool, it’s important to understand the appropriate use cases and limitations.
However, we must recognize that the current vogue of AI represents the next, not the final, step in computing intelligence.
TL;DR: We’re not dead yet.
I love to hear from my community. Especially when you disagree. Let’s chat. Here’s my calendar.